ช่วงนี้คนใช้ LLM กันหนักขึ้นเรื่อย ๆ แล้วก็ตามมาด้วย “อาการ” ที่น่าหงุดหงิดที่สุดอย่างหนึ่ง: hallucination — คือมันตอบ ลื่นมาก… แต่ “มั่นใจผิด” แบบหน้าตาย
หลายคนพยายามแก้ด้วย prompt เท่ ๆ อย่าง “ตอบให้ถูกนะ” หรือ “ห้ามมั่ว” — ข่าวร้ายคือมันช่วยได้บ้าง แต่ไม่พอ ข่าวดีคือเราลด hallucination ได้จริง ถ้าคิดแบบ “ระบบ” ไม่ใช่แค่ “คำสั่ง”
บทความนี้สรุปเป็นแนวทางที่เอาไปใช้ได้ทันที (ไม่ว่าจะใช้ ChatGPT/Claude/Gemini หรือทำเป็น agent ต่อกับ tools) พร้อมภาพ checklist/workflow ประกอบค่ะ
ก่อนอื่น: ทำไม LLM ถึง hallucinate?
เพราะโดยธรรมชาติ LLM เก่งเรื่อง “คาดเดาข้อความถัดไป” ไม่ได้มีสวิตช์ชื่อว่า “รู้/ไม่รู้” แบบมนุษย์ มันเลยมีแนวโน้มจะ เติมช่องว่างให้ครบ แม้ข้อมูลไม่พอ
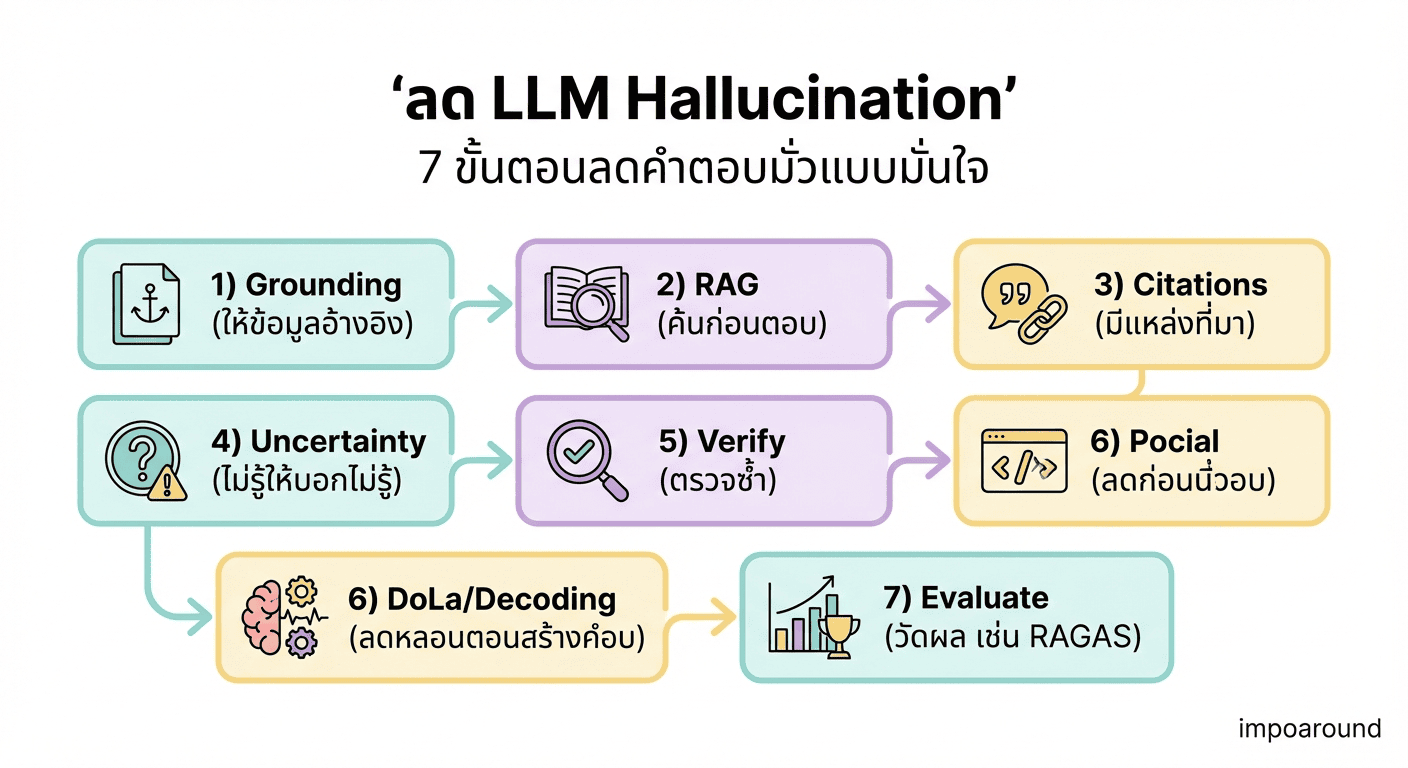
7 วิธีลด hallucination แบบทำจริงได้ (เรียงจากคุ้มสุด → ขั้นเทพ)
1) บังคับให้โมเดล “อ้างจากหลักฐาน” (Grounding)
ถ้าเป็นงานที่ต้องใช้ข้อมูลจริง (ชื่อคน/ราคา/สถิติ/รายละเอียดผลิตภัณฑ์) อย่าปล่อยให้มันตอบจาก “ความจำในโมเดล” อย่างเดียว
แนวคิดคือ: ให้มันตอบ จาก context ที่เราป้อนให้เท่านั้น เช่น paste ข้อมูล/policy/เอกสาร แล้วกำชับว่า
“ตอบโดยอ้างอิงจากข้อความด้านล่างเท่านั้น ถ้าไม่มีข้อมูลให้ตอบว่าไม่แน่ใจ”
2) ใช้ RAG (Retrieval-Augmented Generation) เมื่อคำตอบต้องพึ่ง knowledge
RAG คือให้ระบบ “ค้นข้อมูล” (จากเอกสาร/ฐานความรู้/เว็บ) ก่อน แล้วค่อยให้ LLM สรุปจากสิ่งที่ค้นมา งานสาย knowledge-intensive เช่น Q&A ในองค์กร / สรุปเอกสาร / ตอบคำถามลูกค้า — RAG มักช่วยลด hallucination ได้มาก
แต่ต้องจำไว้: RAG ไม่ใช่ยาวิเศษ ถ้า retrieval หาข้อมูลผิด หรือ context ยัดมั่ว ก็หลอนได้เหมือนเดิม
3) บังคับให้ “ใส่ citation” และจับผิด citation ปลอม
ให้ตอบแบบมี citations/ลิงก์อ้างอิง แล้วทำขั้นตอน check สั้น ๆ เช่น
- ลิงก์มีอยู่จริงไหม
- อ้างอิงตรงกับประโยคที่กล่าวอ้างไหม
ถ้าทำเป็น workflow/agent: แยก step “ตอบ” กับ “verify” ออกจากกันจะเวิร์กมาก
4) เพิ่มระบบ “ยอมรับว่าไม่รู้” (Abstain / Uncertainty)
อาการน่ากลัวคือ high-certainty hallucination: ตอบผิดแต่มั่นใจมาก ทางแก้ที่ pragmatic คือทำให้โมเดล “กล้าพูดว่าไม่แน่ใจ” เช่น
- ข้อมูลไม่พอ
- ต้องขอแหล่งอ้างอิงเพิ่ม
- ขอเวลาค้นก่อน
อันนี้สำคัญกว่า “ตอบให้ดูฉลาด” เยอะ โดยเฉพาะงานที่มีผลกระทบจริง
5) ใช้ constrained decoding / เทคนิค inference-time เช่น DoLa
มีเทคนิคที่ช่วยลดการหลอนตอน “ถอดรหัสคำตอบ” (decoding) โดยไม่ต้อง retrain เช่น DoLa (Decoding by Contrasting Layers) ที่เสนอว่าช่วยเพิ่ม factuality ได้
ข้อดี: ไม่ต้องเพิ่มข้อมูล ไม่ต้องเพิ่มเอกสาร
ข้อเสีย: ต้อง implement ระดับโมเดล/infra (ไม่ใช่ทุกคนทำได้ในแชทปกติ)
6) ทำ self-check / critic step หลังตอบ
ให้โมเดลตอบก่อน แล้วให้มัน (หรืออีกโมเดล) ตรวจคำตอบอีกรอบด้วย prompt แบบ reviewer:
- จุดไหนอาจผิด?
- ประโยคไหนควรมีหลักฐาน?
- ตรงไหนเป็นการเดา?
7) วัดผลด้วย evaluation framework (เช่น RAGAS) แล้วทำให้เป็นนิสัย
ถ้าทำระบบจริง สิ่งที่ทำให้ดีขึ้นแบบต่อเนื่องคือ “วัด” เช่น
- faithfulness (ตอบตรงกับ context ไหม)
- relevance (ตอบตรงคำถามไหม)
- context precision/recall (retrieval ดีไหม)
สรุป
LLM ไม่ได้ “ตั้งใจโกหก” แต่มัน “พยายามตอบให้ลื่น” ถ้าอยากให้มันน่าเชื่อถือขึ้น ต้องทำให้มันมี หลักฐาน + มี ขอบเขตสิทธิ์ + มี ขั้นตอนตรวจสอบ